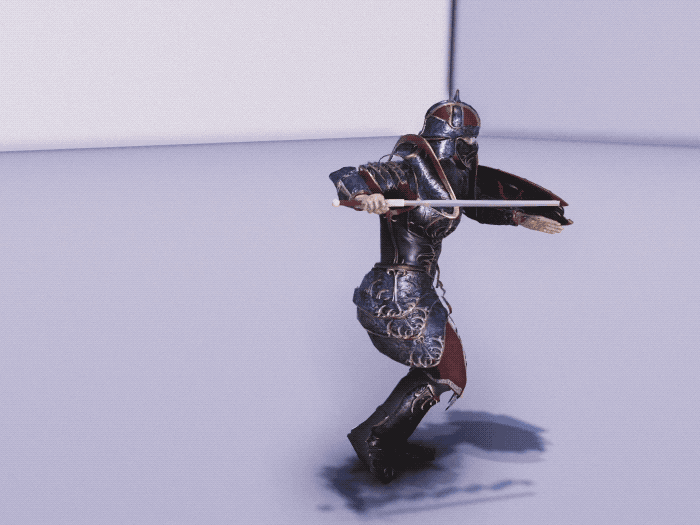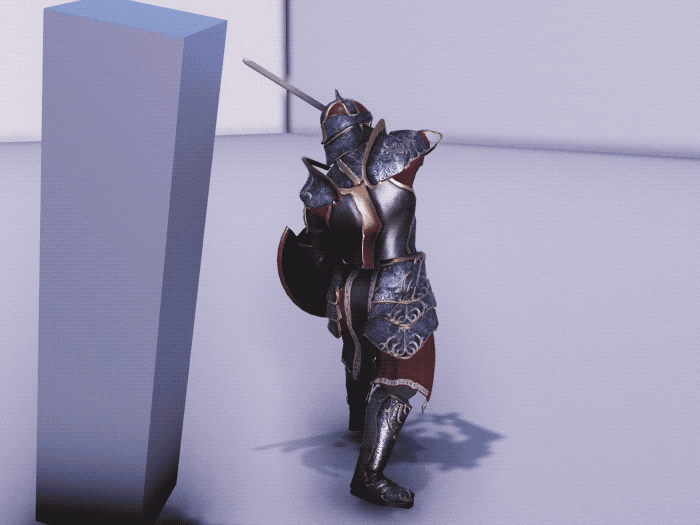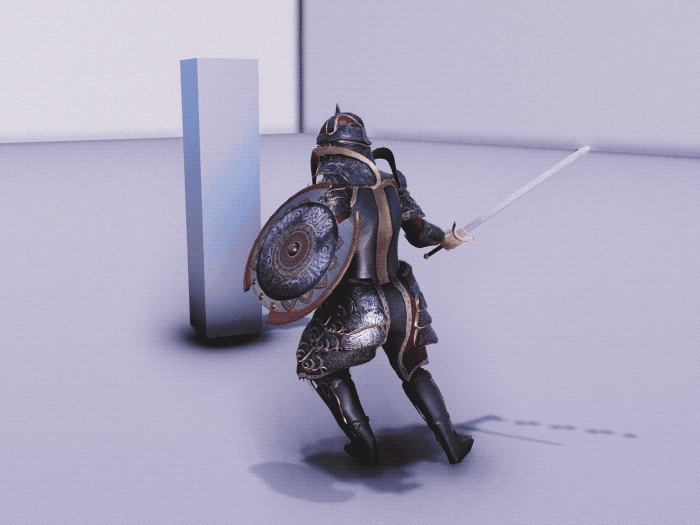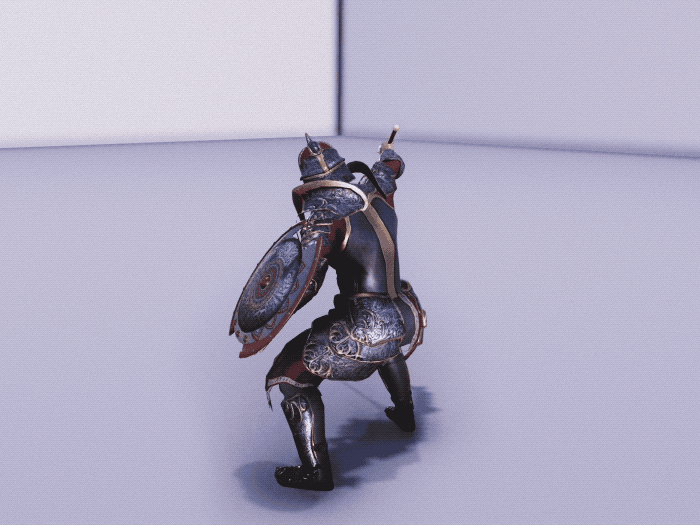Training Imitation Policy by Imitating Life-Like Motion Clips
To control the physics-based character perform lifelike movement, we firstly train an imitation policy to mimic a set of motion clips. Our framework employs a conditional VQ-VAE structure comprising an encoder-decoder and a discrete information bottleneck. This structure enables training the policy to perform a wide range of diverse movements, while keeping the resulting latent space compact, i.e., a codebook. This allows for efficient reuse of the learned movements in downstream tasks. To demonstrate the generality of our framework, we evaluated it on two different humanoid characters, one equipped with a sword and a shield with 37 degrees-of-freedom and another character is equipped with boxing gloves with 34 degrees-of-freedom. The imitation policy is trained separately for each character using motion clips that last about half an hour, including basic movements such as locomotion, as well as specific movements such as a set of attack combos for the actor with a sword and shield, and some boxing skills for the boxer character.